
Using locally powered LLM in your favorite Jetbrains IDEs
I've recently found a good setup for using locally powered LLMs in the IDEs I use every day. Specifically, I almost exclusively use Jetbrains IDEs like Rider, WebStorm, PyCharm, etc. After building a large chunk of my own LLM integration for these IDEs, I have finally found a setup that I wanted via the Open Source plugin called CodeGPT (opens new window).
In this guide, I'll walk you through the steps on how I integrated a locally running Large Language Model (LLM), like the fine-tuned Mistral-7B, into your JetBrains IDE setup. This approach offers the benefits of a powerful AI assistant right in your development environment.
This software can be very fiddly to setup, and is subject to a lot of environment specific issues. I highly recommend that if you are going to use
text-generation-web-ui, you understand that this is rapidly changing project, so can be quite unstable.
# Setting Up the Text Generation Web UI
The first step is to set up the text-generation-web-ui, a handy tool for running your LLM. Here’s how:
Installation: Head over to the text-generation-web-ui GitHub page (opens new window) and follow the instructions to install it. Remember not to use the
--apioption when starting it.Running Locally: Docker is the simplest method for Linux users, but there are also shell and batch scripts for local development machines.
Configuration:
- The default API port is 5000, as shown in the example .env file (opens new window). Feel free to change this in your
.envfile if necessary. For instance, I use port 5010. - Load your desired model, like Mistral-7B-OpenOrca (opens new window), to avoid common errors such as "No tokenizer is loaded."
- The default API port is 5000, as shown in the example .env file (opens new window). Feel free to change this in your
Session Setup: Under
Session, choose the "openai" option, apply the changes, and restart.
# Troubleshooting
I ran into several issues trying to get text-generation-web-ui to work with the OpenAI option selection, below are a few of the issues I hit and the steps I took to resolve.
- Missing
sentence_transformersand causes it to fail to restart with OpenAI support.- Update the
requirements.txtand usedocker compose up -d --buildto rebuild and restart your container
- Update the
- Missing
tiktoken, this can still come up looking like an issue withsentence_transformers- Update the
requirements.txtand usedocker compose up -d --buildto rebuild and restart your container
- Update the
- Missing
sse_starlette- Update the
requirements.txtand usedocker compose up -d --buildto rebuild and restart your container
- Update the
Be sure to update the requirements.txt rather than use docker exec -it {containerID} /bin/bash to install using pip install x as I found this just didn't work.
The final requirements additions I had were adding the below list of python packages (minus all the specific git installs) at the top of my requirements.txt:
accelerate==0.24.*
colorama
datasets
einops
exllamav2==0.0.7; platform_system != "Darwin" and platform_machine != "x86_64"
gradio==3.50.*
markdown
numpy==1.24.*
optimum==1.13.1
pandas
peft==0.5.*
Pillow>=9.5.0
pyyaml
requests
safetensors==0.4.0
scipy
sentencepiece
sentence_transformers
sse_starlette
tiktoken
tensorboard
transformers==4.35.*
tqdm
wandb
If you are running a Mac or doing your development on Linux, CodeGPT can manage your Llama based models itself and you don't need the above setup.
# Integrating CodeGPT with JetBrains
The CodeGPT extension enhances your JetBrains IDEs with AI capabilities:
# Installation
Download the CodeGPT (opens new window) from the JetBrains Marketplace.
# Configuration
CodeGPT supports OpenAI but allows for local service configuration. This feature is especially useful if you’re running models on a separate machine.
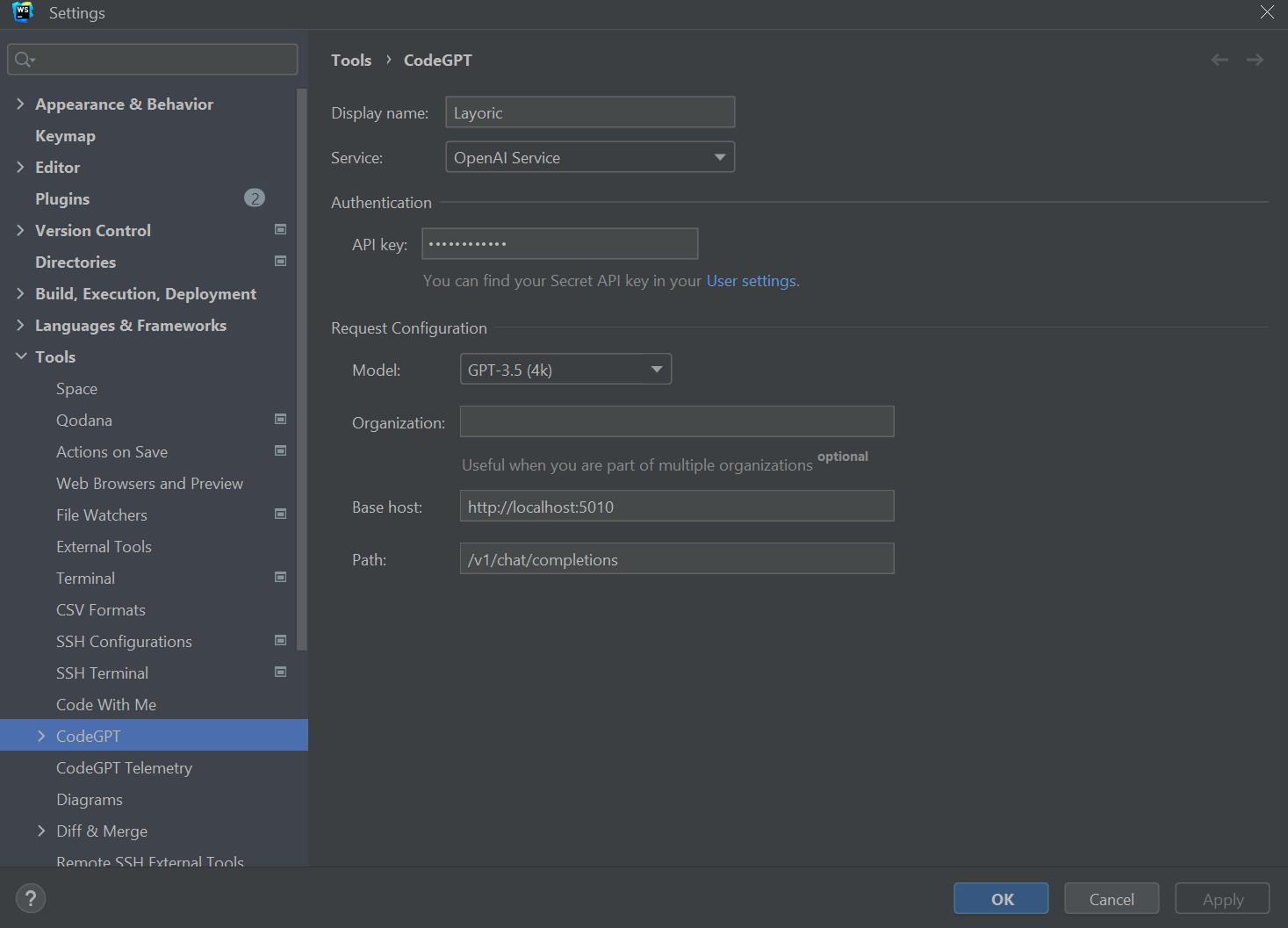
You'll want to override the Base host and provide a dummy API key. Neither the model selected or the API are used when using text-generation-webui, since that controls which model is loaded, and by default doesn't have any authentication required.
# For Linux and Mac Users
On Linux or Mac, CodeGPT can manage and install Llama-based models via Llama.Cpp, which might eliminate the need for text-generation-webui.
This setup is ideal for Mac users with M1, M2, or M3 CPUs and at least 24GB of RAM since even a 7B model quantized will take up ~4GB of memory.
# Model Compatibility
Note that Mistral and similar models are not Llama-based and might not work with this setup. However, smaller Llama models are still effective coding assistants.